Highlights
- Built an end-to-end RGB plus robot-state learning pipeline for Franka manipulation, predicting 8-step future joint deltas and end-effector trajectories from 4 context frames/states.
- Implemented a TemporalVisionFrankaPolicy with a CNN image encoder, state projection, Transformer temporal fusion, joint-delta rollout head, and end-effector prediction head.
- Created an Isaac Sim data workflow with brighter multi-episode collection, merged JSONL indexes, episode-level validation, continuity filters, image preprocessing, and modality ablations.
- Trained the advanced run for 100 epochs and reached a best validation terminal end-effector distance of 1.67 cm with a 1.37 cm mean trajectory end-effector distance across 976 validation windows.
- Validated that visual context contributes to the model: removing RGB increased terminal end-effector error by about 1.49x, while removing state/cube context caused order-of-magnitude degradation.
Key metrics
Media
Tech stack
Objective
The goal of this project is to make robotic manipulation models more physically grounded by tying visual observations to differentiable state prediction and rollout losses. Instead of treating perception and control as separate blocks, the system asks whether an RGB-conditioned policy can learn multi-step robot motion while remaining inspectable through simulation metrics and ablations.
The final portfolio version presents the project as a research-style report page: it explains the robotics problem, shows the architecture, documents the Isaac Sim data workflow, visualizes training behavior, and summarizes ablation evidence from the saved run artifacts.
Problem and motivation
Contact-rich manipulation is hard because the policy must reason about geometry, object state, physical interaction, robot kinematics, and future consequences of actions. Pure image models can learn correlations, but they often hide whether the model is using visual evidence, robot state, or dataset shortcuts.
This project focuses on the bridge between visual learning and physics-aware prediction. The code base starts with runnable differentiable-physics demos, then extends the idea toward Isaac Sim Franka manipulation with temporal context, multi-step supervision, continuity filtering, and modality ablations.
System architecture
- Input: a temporal context of 4 RGB frames plus robot joint positions, end-effector position, cube/object position, target position, and a normalized time token.
- Vision branch: a lightweight CNN encoder converts each frame into a compact visual feature vector that can be trained without external pretrained dependencies.
- State branch: robot and scene state are projected into the same embedding space as the vision features.
- Temporal fusion: a 2-layer, 4-head Transformer encoder fuses the context window and produces a sequence-level summary.
- Prediction heads: the model predicts bounded future joint deltas for rollout integration and future end-effector positions for trajectory-level supervision.
Isaac Sim data and sequence pipeline
The project includes an Isaac Sim Franka workflow for collecting RGB frames and robot/cube/end-effector trajectories, converting episodes into training indexes, merging multiple episodes, and inspecting sequence quality before training.
A major engineering improvement was treating sequence quality as a first-class issue. The dataset loader splits merged JSONL indexes back into episode trajectories, supports episode-level train/validation splits, and rejects windows with impossible end-effector or joint jumps so the temporal model is not trained across reset boundaries.
- Bright collection workflow: stronger lighting, camera look-at setup, visual randomization, debug previews, and percentile image preprocessing for under-exposed frames.
- Sequence settings: image size 128, batch size 8, context length 4, horizon 8, stride 1, validation fraction 0.2, and episode-level split mode.
- Continuity filters: reject windows with excessive end-effector jumps or joint-space jumps before constructing multi-step targets.
Temporal vision model
The core model is a TemporalVisionFrankaPolicy. It encodes each context frame using a CNN, combines those visual features with projected state vectors, adds learned positional embeddings, and passes the context through a Transformer encoder. The last token summary drives two prediction heads: one for future joint deltas and one for future end-effector coordinates.
The architecture is intentionally practical: the image encoder is compact, the Transformer is modest enough to train on project-scale data, and the prediction heads expose interpretable quantities that can be plotted and compared against future trajectories.
Differentiable physics and rollout losses
The training objective combines multiple physical consistency signals instead of relying on one scalar loss. Predicted joint deltas are integrated into future joint trajectories, end-effector predictions are compared across the horizon, terminal end-effector error receives extra weight, smoothness discourages jittery actions, and joint-limit regularization keeps predictions physically plausible.
The repository also includes differentiable physics scaffolding beyond the Franka sequence model: a PyTorch Gaussian splatting renderer for visual-loss wiring, an optional NVIDIA Warp planar-arm engine, and local proxy robot-arm training scripts that provide a fast path before heavier simulator integration.
Training results
The saved advanced Isaac Franka bright-many run trained for 100 epochs. The best validation checkpoint occurred at epoch 97, reaching 1.67 cm terminal end-effector distance and 1.37 cm mean end-effector distance across the future trajectory. The final epoch remained close, ending at 1.71 cm terminal end-effector distance and 1.39 cm mean end-effector distance.
The loss curve shows the model moving from a high initial terminal error into a stable centimeter-level validation regime. The rollout plot compares predicted and target end-effector x/y/z coordinates over the future horizon and exposes where the model tracks well versus where longer-horizon transitions remain difficult.
Ablation findings
The ablation run evaluated 976 validation windows. The full model achieved a 1.67 cm terminal end-effector distance. Zeroing RGB context increased terminal error to 2.49 cm, showing that visual information contributes to the policy even though robot state is still very informative.
The stronger ablations show that the task is not solvable from vision alone in the current formulation. Removing joint state, end-effector/cube state, or the full state vector increases terminal error by more than an order of magnitude, which is a useful engineering signal: the next version should make action/state conditioning explicit and collect more diverse visual episodes before claiming strong vision-only generalization.
Engineering contribution
- Implemented the temporal sequence dataset, model, training loop, metrics logging, checkpointing, rollout visualization, and modality-ablation evaluation workflow.
- Added Isaac Sim data-collection utilities, merged-index tooling, path-repair scripts, dark-frame diagnostics, and generated-data hygiene so the repository stays usable as experiments grow.
- Documented practical lessons around lighting, camera placement, episode-level validation, reset-boundary filtering, and the difference between a visually attractive demo and a learnable sequence dataset.
- Packaged the project page with a cover image, architecture visual, visual-property concept figure, optimization progression image, training curve, rollout plot, ablation chart, and concise research-style narrative.
Limitations and next steps
- The current best results are from simulator-generated Franka sequences, not a physical robot deployment.
- The model still relies heavily on robot state, so the next iteration should add richer visual diversity, multi-camera inputs, and action-conditioned prediction.
- The differentiable FK prior is scaffolded but should be calibrated from the actual Isaac/URDF transforms before enabling stronger FK consistency losses.
- Future work should add closed-loop Isaac replay, action-conditioned rollouts, 50-100 brighter randomized episodes, production-grade 3DGS rendering, and real-robot validation.
Related projects

Automated Goalie: Ping Pong Ball Trajectory Prediction System
Robotics · 2025
A closed-loop robot-learning prototype that detects a ping pong ball, estimates its 3D motion, predicts the landing point, and rotates a servo-driven blocker in real time on a Raspberry Pi-based hardware setup.
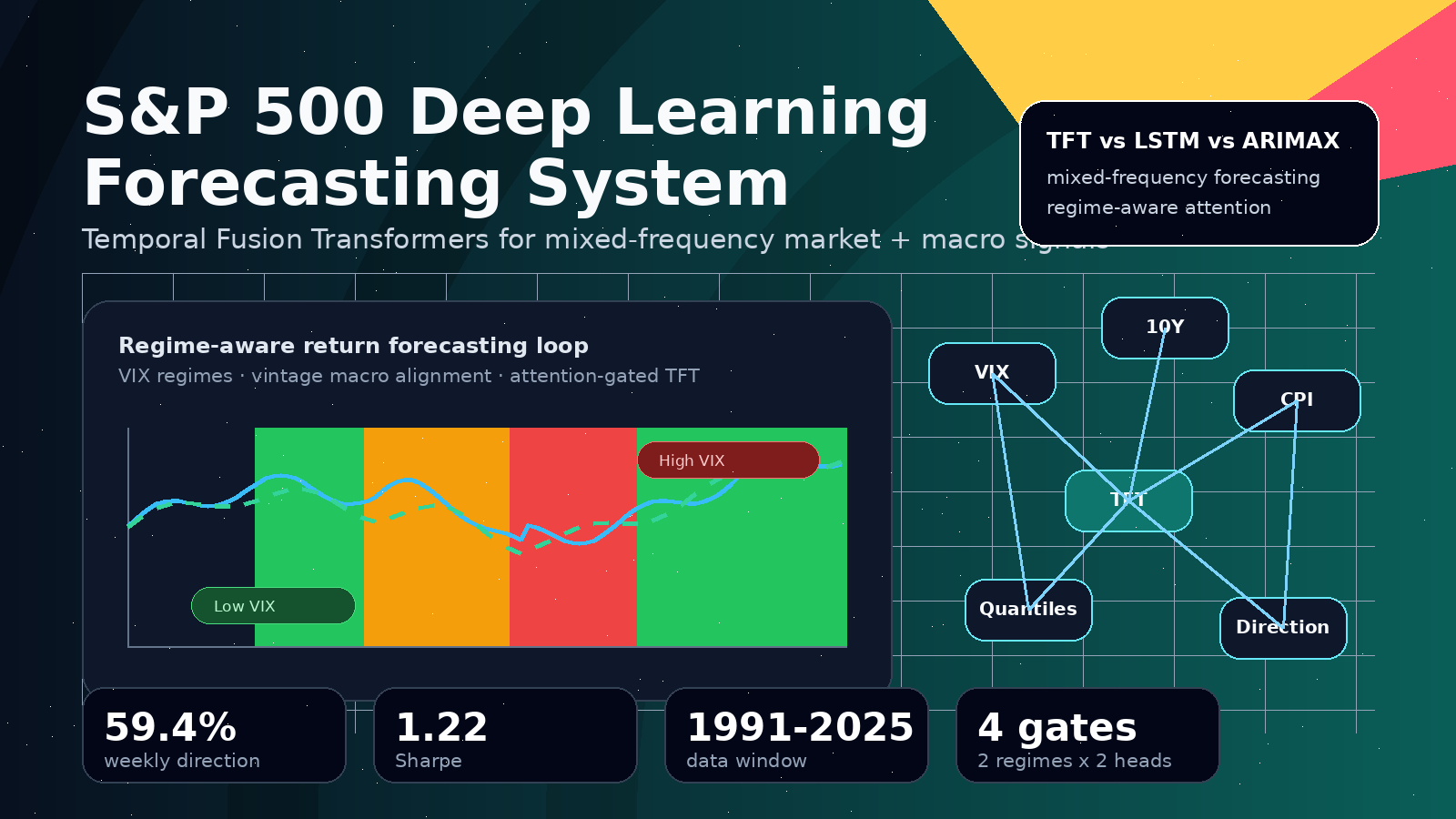
S&P 500 Deep Learning Forecasting System
Financial ML · 2025
A research-grade forecasting system that evaluates Temporal Fusion Transformers against LSTM and ARIMAX baselines for S&P 500 return prediction using mixed-frequency market and macroeconomic data, then extends TFT with regime-aware attention and interpretability diagnostics.
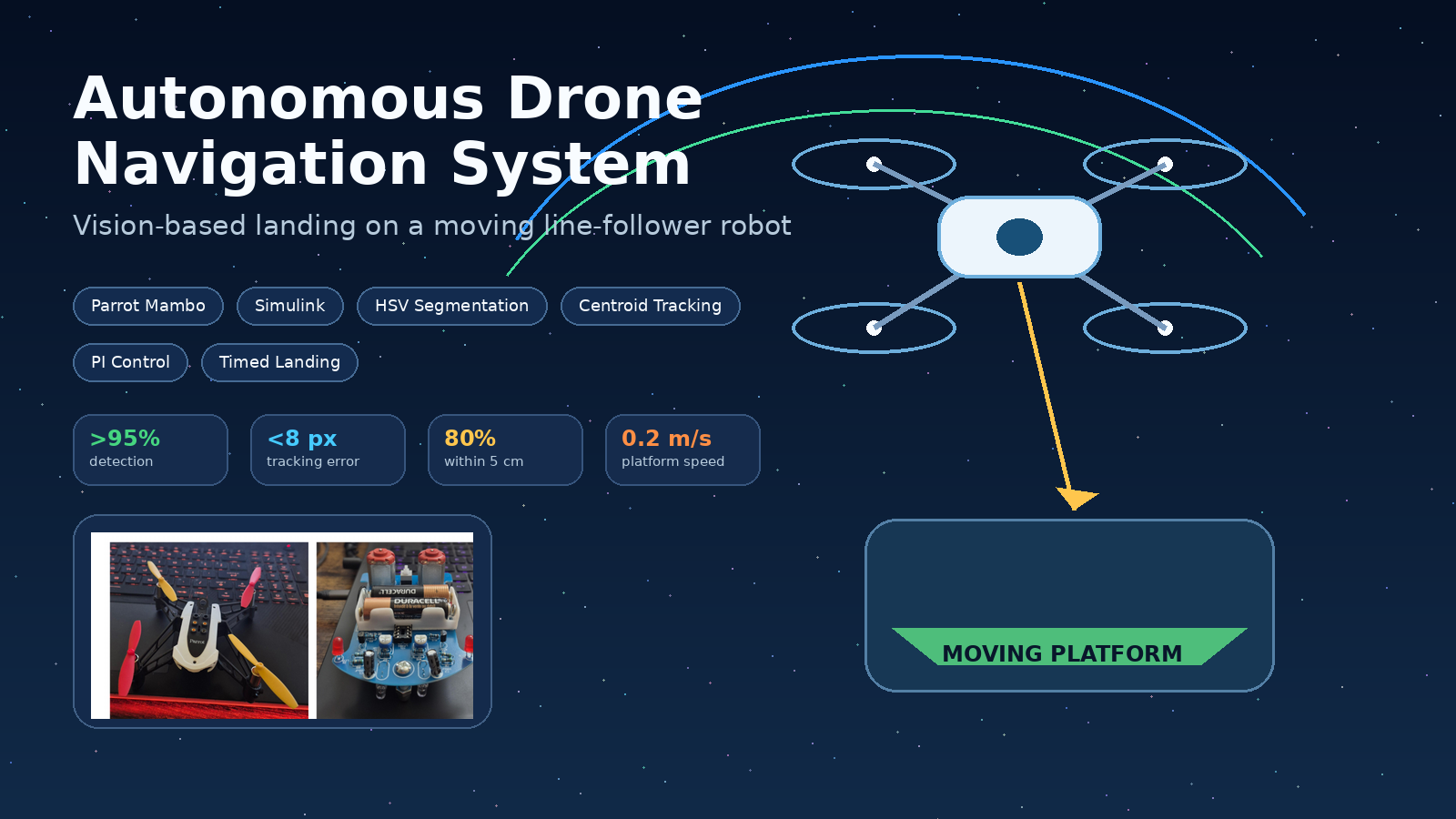
Autonomous Drone Navigation System
Robotics · 2025
A vision-based landing system where a Parrot Mambo drone tracks a moving line-follower robot, stays aligned using image feedback, and executes a timed descent onto the platform.
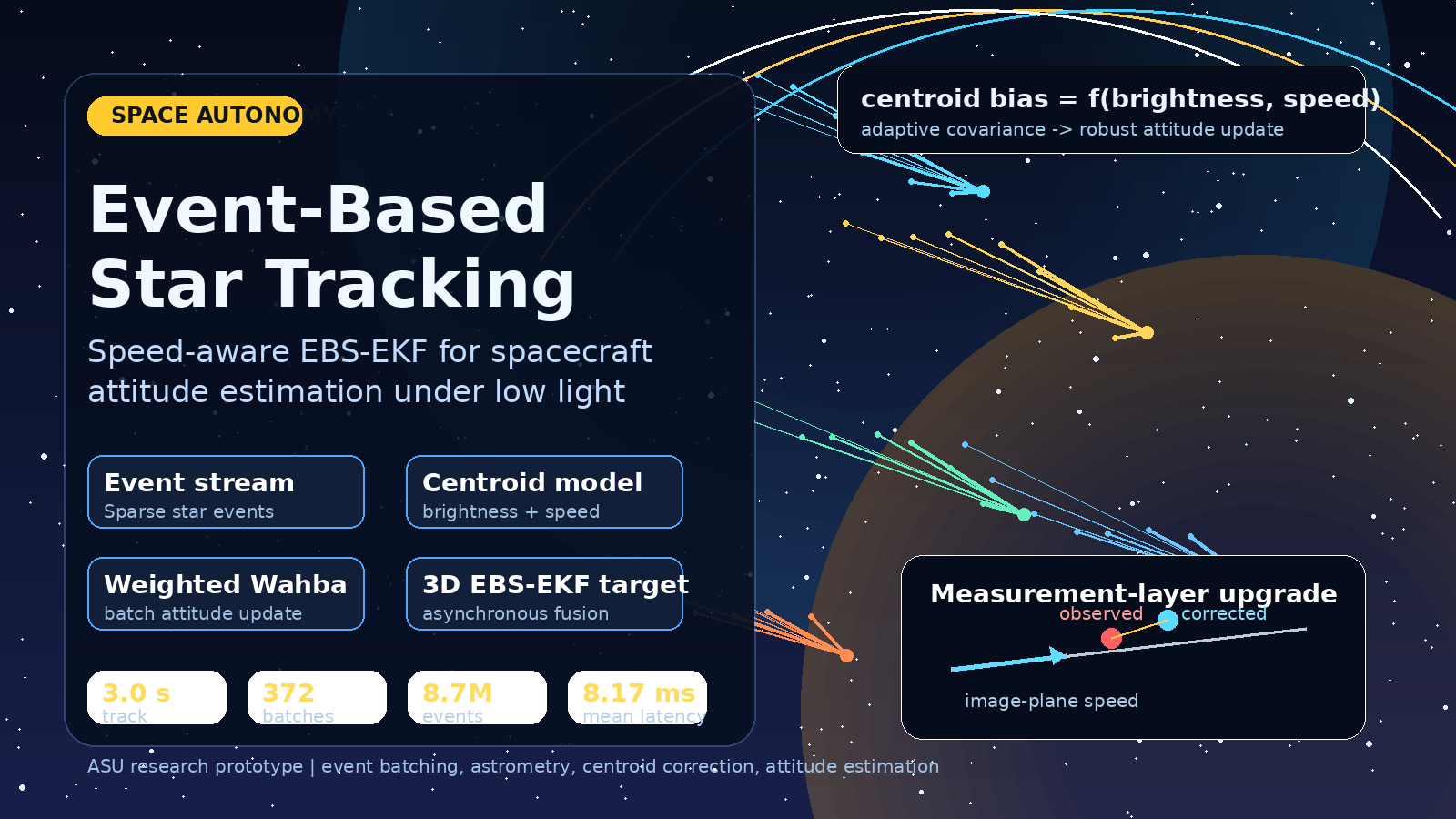
Event-Based Star Tracking for Spacecraft Attitude Estimation
Space Autonomy · 2026
A Speed-Aware EBS-EKF research prototype for event-camera star tracking that improves low-light spacecraft attitude estimation by making centroid correction depend on both brightness and image-plane speed.